我们使用缓存来降低请求的响应时间,分布式缓存怎么做(Redis Cluster和Codis),数据一致性如何保证?
1. 缓存介绍
1.1 为什么使用缓存
降低请求的响应时间,提升用户体验,减少对固化存储的读压力
1.2 缓存适用场景
- 静态资源
- 较少更改的资源
- 读多写少
1.3 缓存类别
- 本地缓存
- 作用
- 静态不变的数据
- 减少网络I/O交互
- 例如:电商网站的分类信息
- Google Guava Cache
- 作用
- 分布式缓存
- 作用
- 缓存相对静态的数据
- 缓存数据量较大,单机无法存放的数据
- 提高查询速度
- Memcached、Redis
- 作用
2 分布式缓存实现
2.1 Redis Cluster
Redis Cluster 是 Redis 的分布式解决方案,在 3.0 版本正式推出,有效地解决了 Redis 分布式方面的需求。
数据分片
Sharding采用预分配16384个槽slot,根据crc16(key) mod 16384的值,决定key存放在哪个slot里;
集群只有在所有槽位都有主节点处理时才能上线并处理数据。
命令执行
槽位正确:命令处理的key正好由接受命令的节点负责,直接处理;
槽位不正确:key所在的槽并非由当前节点负责,向客户端返回Redirection,客户端根据Redirection转至新节点。
Redirection实现
- Gossip协议(最终一致性算法)包含多种消息,包括ping,pong,meet,fail等等,用于失败检测、路由同步、Pub/Sub、动态负载均衡等
- 节点间通过Gossip协议通信,每个节点都知道集群中包含哪些节点,以及这些节点的状态
故障转移
部署时通常需要把节点部署成主从模式,以便在故障时快速恢复
- 集群中某主节点宕机
- 从宕机节点所有从节点选择一个节点
- 该从节点执行SLAVEOF onone命令,成为新的主节点
- 新的主节点会撤销所有对宕机节点的槽指派,并全部指派给自己
- 新的主节点向集群广播PONG消息
- 新的主节点开始接受并处理自己负责的槽有关的命令
2.2 Codis
和Redis cluster不同,Codis采用一层无状态的proxy层,将分布式逻辑写在proxy上,底层的存储引擎还是Redis本身,数据的分布状态存储于zookeeper(etcd)中。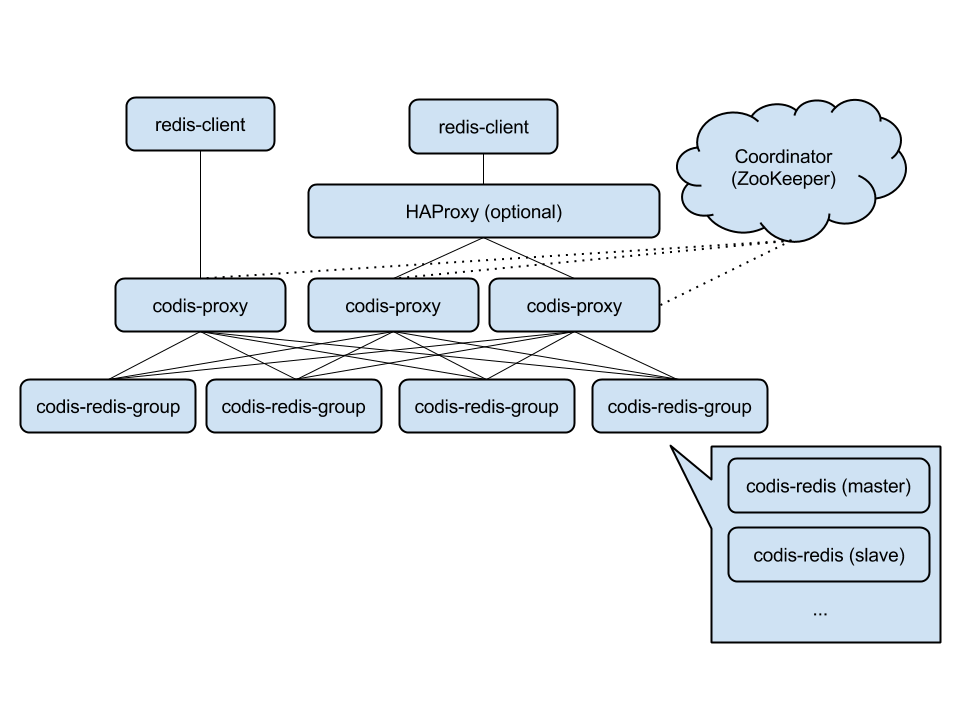
- 数据分片:Codis 采用 Pre-sharding 的技术来实现数据的分片,默认分成 1024 个 slots (0-1023),SlotId = crc32(key) % 1024
- 支持动态水平扩展,对client完全透明不影响服务的情况下可以完成增减redis实例的操作
- 故障转移:Redis主从使用Redis的Sentinel监控,发现问题后触发更改metadata
- 负载均衡:提供了运维工具自动rebalance slot
- 运维工具、图形监控界面
3 缓存数据一致性
数据多份存储:数据库、缓存,如何保证数据库与缓存的一致性
强一致性?
通过2PC等实现强一致性,不适用互联网业务高吞吐量、低延迟的要求
时序控制?
先删除缓存,然后再更新数据库,而后续的操作会把数据再装载的缓存中。看起来没有问题,但是假如两个并发操作,一个是更新操作,另一个是查询操作,更新操作删除缓存后,查询操作没有命中缓存,先把老数据读出来后放到缓存中,然后更新操作更新了数据库。于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了。
最终一致性保证
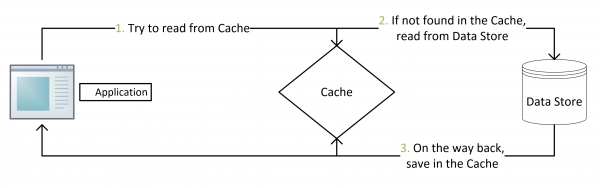
读请求
- 先读缓存,命中缓存则直接返回
- 不命中,读数据库,把结果回填缓存中
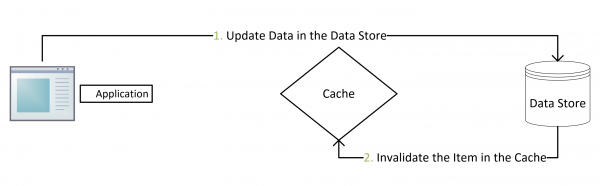
写请求
- 更新数据库,然后立即delete缓存项
- X秒钟后,再次delete缓存项(双重失效,保证成功率)
- 缓存delete失败的记录日志、脚本定期修正
设置缓存Expired Time
- 根据业务特点设置
- 同时要注意缓存集中失效的问题,可在过期时间上增加随机量
