为什么会产生分布式问题,有哪些常见的解决方案?
1. 什么是分布式事务问题
随着业务需求和架构的变化,单体应用被拆分为微服务,一个大型业务系统往往由若干个子系统构成,这些子系统又拥有各自独立的数据库。往往一个业务流程需要由多个子系统共同完成,而且这些操作可能需要在一个事务中完成。此时,每一个服务内部的数据一致性仍由本地事务来保证,整个业务层面的全局数据一致性就需要一个分布式事务的解决方案来保证。
2. 分布式事务分类
2.1 刚性分布式事务
满足传统事务特性ACID
XA模型
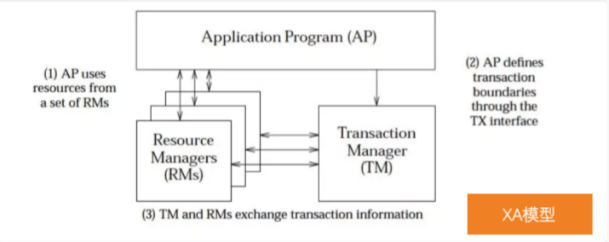
- X/Open 组织(即现在的 Open Group )定义了分布式事务处理模型XA
- 应用程序(AP)定义事务边界并访问事务边界内的资源
- 资源管理器(RM)管理计算机共享的资源,即数据库等
- 事务管理器(TM)负责管理全局事务,分配事务唯一标志,监控事务的执行进度,负责事务的提交、回滚、失败恢复等
2PC
要求数据库提供对 XA 的支持,锁定周期长,并且需要应用服务器支持如WebLogic/WebSphere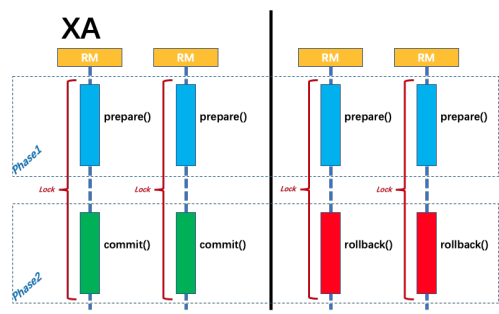
- 二阶段提交,是XA规范标准实现
- TM发起prepare投票
- RM都同意后,TM再发起commit
- Commit过程出现宕机等异常,节点服务重启后,根据XA recover再次进行commit补偿
2.2 柔性分布式事务
柔性事务是对XA协议的妥协,通过降低强一致性要求,从而降低数据库资源锁定时间,提升可用性
TCC模型
完全由业务实现,每个子业务都需要实现Try-Confirm-Cancel三个接口,对业务侵入大
- Try 尝试执行业务,执行业务检查,预留必要的业务资源
- Confirm:真正执行业务,不再做业务检查
- Cancel:释放Try阶段预留的业务资源
Saga模型
把一个分布式事务拆分为多个本地事务,每个本地事务都有相应的执行模块和补偿模块,当Saga中任意一个本地事务出错时,可以通过调用相关的补偿方法恢复之前的事务。
当每个Saga子事务T1, T2, …,Tn都有对应的补偿定义C1, C2, …,Cn-1,则有
- 最佳情况:子事务序列T1, T2, …,Tn全部完成
- 失败恢复:T1, T2, …,Tj, Cj-1, …, C2, C1 得以完成
Saga隔离性
Saga本身不保证隔离性,需由业务层控制并发:加锁或者预先冻结资源
Saga恢复方式
- 向后恢复:补偿所有已完成的事务
- 向前恢复:重试失败的事务,假设每个子事务最终都会成功
2.3 刚性分布式事务VS柔性分布式事务
| 刚性事务(XA) | 柔性事务 | |
|---|---|---|
| 业务改造 | 无 | 有 |
| 回滚 | 支持 | 实现补偿接口 |
| 一致性 | 强一致性 | 最终一致性 |
| 隔离性 | 原生支持 | 实现资源锁定接口 |
| 并发性能 | 严重衰退 | 略微衰退 |
| 适合场景 | 短事务,低并发 | 长事务,高并发 |
3. 异步场景分布式事务设计
3.1 可靠消息最终一致性
MQ提供类似XA的分布式事务功能,发送方在业务执行开始会先向消息队列中投递 “半消息”,半消息即“暂不能投递”状态的消息,需要发送方根据本地事务执行的结果向MQ服务提交二次确认,才会执行发送或者删除消息的操作。
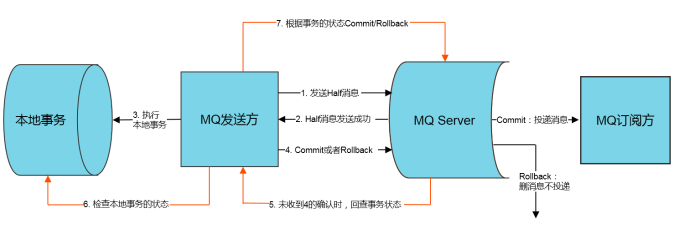
- 优点:较为通用
- 缺点:业务方需要提供回查接口,发送消息At least once,消费端需处理幂等,MQ需支持事务消息
3.2 本地事务消息表
本地操作和发送消息通过本地事务强一致性。
本地事务提交时,将业务数据和消息数据一同写入本地数据库,再从消息表读取消息写入MQ。
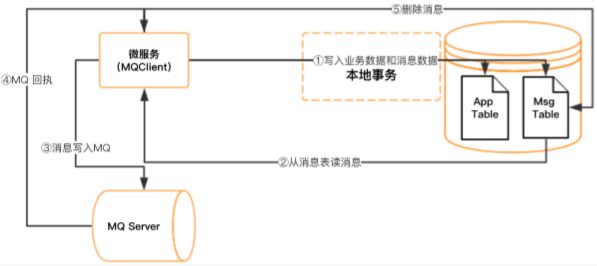
- 优点:业务侵入性小,无需MQ支持事务消息
- 缺点:发送端消息At least once,消费端需处理幂等
4. 同步场景分布式事务设计
4.1 基于异步补偿的分布式事务
记录请求调用链条+提供幂等补偿接口+补偿机制。
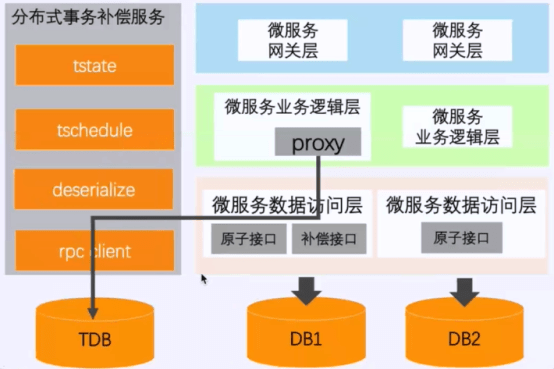
基本原理
- 通过一个分布式事务补偿服务,记录全局事务组和请求调用参数在远端数据库TDB
- 在真正业务逻辑被调用前,生成一个全局唯一的TXID标识事务组->TDB
- 在调用数据访问层之前记录当前调用请求参数->TDB
- 业务正常:调用完成后,当前的调用记录存档或删除
- 业务异常:查询调用链反向补偿
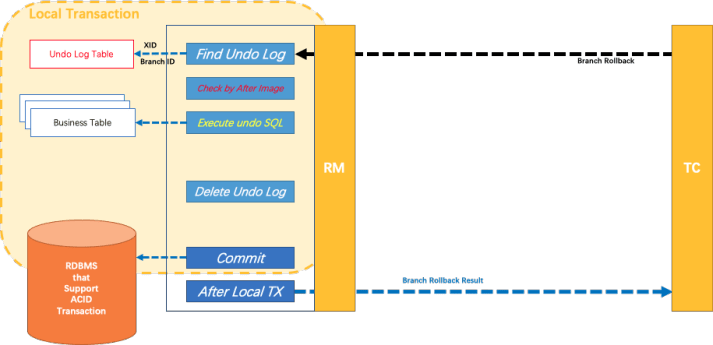
4.2 seata(Fescar)
可参考阿里巴巴开源的分布式事务中间件Fescar,https://github.com/seata/seata/wiki/%E6%A6%82%E8%A7%88
类似上述基于异步补偿的分布式事务,但Fescar的 JDBC 数据源代理通过对业务 SQL 的解析,把业务数据在更新前后的数据镜像组织成回滚日志,在回滚时通过回滚日志生成反向的更新 SQL 并执行,无需额外提供补偿接口,对业务无侵入性。