一些常见的Java应用问题排查工具和问题排查思路。
1. Java线程堆栈
jstack 用于生成java虚拟机当前时刻的线程快照。线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。
1.1 Java线程
- JVM创建的线程
- Attach Listener、Signal Dispatcher、Low Memory Detector、CompilerThread0、Finalizer
- Java用户线程
- 排查问题时主要关注的地方
- 线程堆栈第一行

- tid可以理解为语言层面的线程id
- nid(Native Thread)是JVM的本地线程堆栈
- pstack {Java进程号}

- nid(16进制) == LWP(10进制)
- 线程调用含义

1.2 锁
- 一个线程占有一个锁时,堆栈会打印:
locked <0xe74023b9> - 该线程等待别的线程释放锁时,堆栈会打印:
waiting to lock <0xe74023b9> - 代码中有wait()调用,堆栈会打印:
waiting on <0xe74023b9>
1.3 线程状态
| 线程状态 | 执行操作 | cpu消耗 |
|---|---|---|
| RUNNABLE | 执行java代码、Native(网络IO)、JNI | 不确定cpu消耗 |
| TIMED_WAITING (on object monitor) | obj.wait(time) | 不消耗cpu |
| TIMED_WAITING (sleeping) | Thread.sleep(time) | 不消耗cpu |
| TIMED_WAITING (parking) | 被挂起 | 不消耗cpu |
| WAITING (on object monitor) | obj.wait() | 不消耗cpu |
| BLOCKED (on object monitor) | 等待监视锁 | 不消耗cpu |
2. 分析性能瓶颈
2.1 线程死锁分析
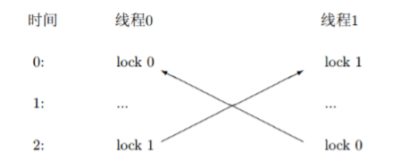
线程死锁的原因很简单,两个线程各自持有锁,然后等待获取对方的锁。
Java堆栈能直接给出结果
1 | Found one Java-level deadlock: |
2.2 代码死循环导致CPU过高分析
常见原因
- HashMap等线程不安全容器,多线程并发读写
- 共享变量没有加锁,多线程并发读写,while、for等退出条件不满足
定位方法一
- 获取一次堆栈
- 间隔一定时间再次获取堆栈
- 去除掉wait、sleep的线程
- 比较两次堆栈,找出一直活跃的线程
定位方法二
- ps -aux |grep 进程名,得到[java进程号]
- top -p [java进程号]
- shift+h 打印出所有线程的CPU统计
- 找出cpu占用率高的线程pid(LWP)
- LWP=nid在堆栈信息中找出对应的java线程
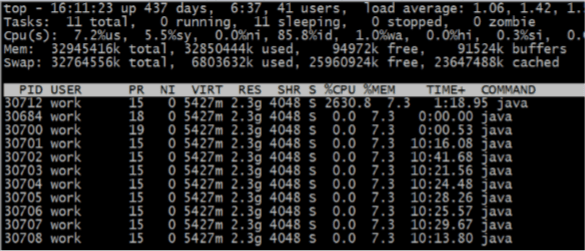
2.3 资源不足导致的性能下降
大量的线程停在同样的调用上下文上
原因:
- 资源配置过少,并发高
- 线程占用资源时间过长
- 代码设计不合理,没有及时释放资源
- 异常情况下未关闭资源
- 内存泄漏导致频繁gc
3. 线上问题处理
线上问题处理步骤:发现问题->保留现场->快速恢复->排查解决->验证
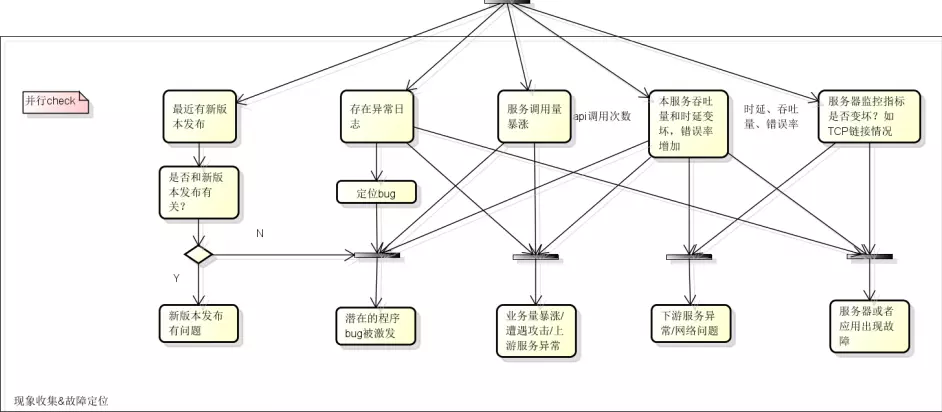
3.1 问题定位
如果有日志报错,则能很好的定位问题,只需根据报错的堆栈信息来解决问题即可;
如果日志没有任何异常信息:
检查最近是否有版本发布、服务调用量情况、服务吞吐量和时延、服务器监控指标等
保存现场
3.2 保存现场
在重启服务前进行保存现场操作,包括保存当前线程的快照和保存JVM内存堆栈快照:
- 保存当前运行线程的快照,可以使用jstack [pid]命令实现,在通常情况下需要保存三份不同时刻的线程快照,时间间隔为1~2分钟。
- 保存JVM内存堆栈快照,可以使用jmap –heap、jmap –histo、jmap -dump:format=b、file=xxx.hprof等命令实现。
- 如果线上服务器资源较多,也可以隔离出1~2台服务器,用作后续问题重现和排查
3.3 快速恢复
根据定位情况决定采取回退版本、紧急修复、服务扩容降级、服务熔断等手段,优先保证线上服务正常运行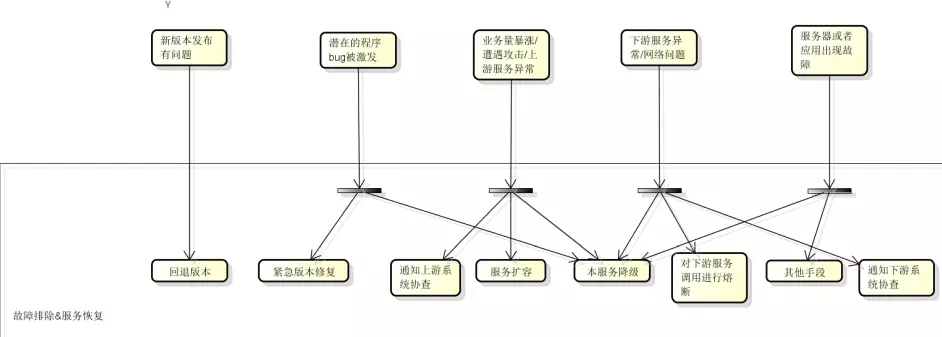
3.4 排查解决
经过上面的一系列操作,线上服务已经暂时恢复,接下来需要排查问题所在
服务器层面排查
主要是CPU、内存、网络连接、磁盘等指标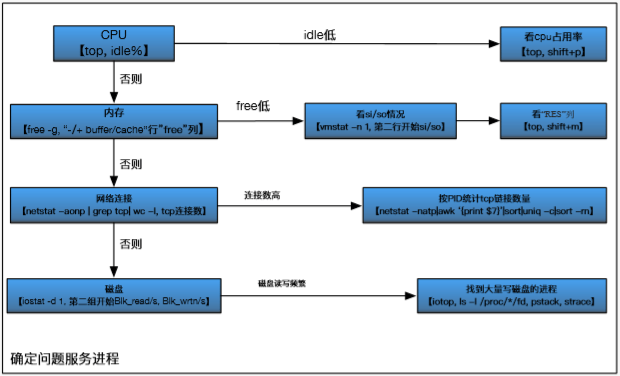
- top
- free -h
- netstat -antp |grep ESTABLISHED |wc -l
- iostat -d 1
java进程层面的排查
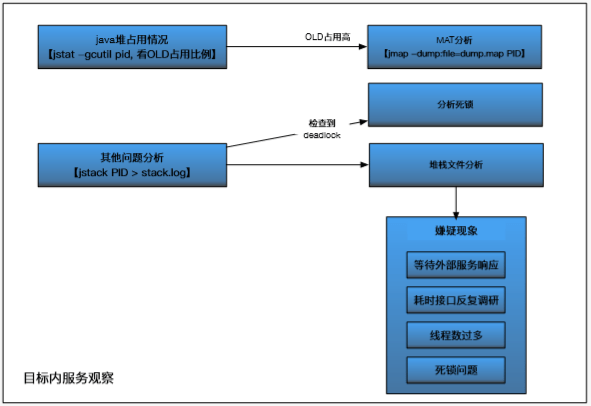
4. 为故障和失败做设计
错误无法避免,故障发生时尽可能维持系统核心功能的可用性
- 设置合理的超时机制
- 自身服务的降级策略
- 对依赖服务的熔断策略
